Regression
If you want to follow along with this example, you can download the data below:
You can also download a complete .zip file with a finished R Markdown file that you can knit and play with on your own:
Live coding example
Complete code
(This is a heavily cleaned up and annotated version of the code from the video.)
Introduction
SAT scores have long been a major factor in college admissions, under the assumption that students with higher test scores will perform better in college and receive a higher GPA. The SAT’s popularity has dropped in recent years, though, and this summer, the University of Chicago announced that it would stop requiring SAT scores for all prospective undergraduates.
Educational Testing Service (ETS), the creator of the SAT, collected SAT scores, high school GPAs, and freshman-year-college GPAs for 1,000 students at an unnamed university.1
You are a university admissions officer and you are curious if SAT scores really do predict college performance. You’re also interested in other factors that could influence student performance.
The data contains 6 variables:
sex: The sex of the student (male or female; female is the base case)sat_verbal: The student’s percentile score in the verbal section of the SATsat_math: The student’s percentile score in the math section of the SATsat_total:sat_verbal+sat_mathgpa_hs: The student’s GPA in high school at graduationgpa_fy: The student’s GPA at the end of their freshman year
# First we load the libraries and data
library(tidyverse) # This lets you create plots with ggplot, manipulate data, etc.
library(broom) # This lets you convert regression models into nice tables
library(modelsummary) # This lets you combine multiple regression models into a single table# Load the data.
# It'd be a good idea to click on the "sat_gpa" object in the Environment panel
# in RStudio to see what the data looks like after you load it.
sat_gpa <- read_csv("data/sat_gpa.csv")Exploratory questions
How well do SAT scores correlate with freshman GPA?
# Note the syntax here with the $. That lets you access columns. The general
# pattern is name_of_data_set$name_of_column
cor(sat_gpa$gpa_fy, sat_gpa$sat_total)## [1] 0.46SAT scores and first-year college GPA are moderately positively correlated (r = 0.46). As one goes up, the other also tends to go up.
Here’s what that relationship looks like:
ggplot(sat_gpa, aes(x = sat_total, y = gpa_fy)) +
geom_point(size = 0.5) +
geom_smooth(method = "lm", se = FALSE) +
labs(x = "Total SAT score", y = "Freshman GPA")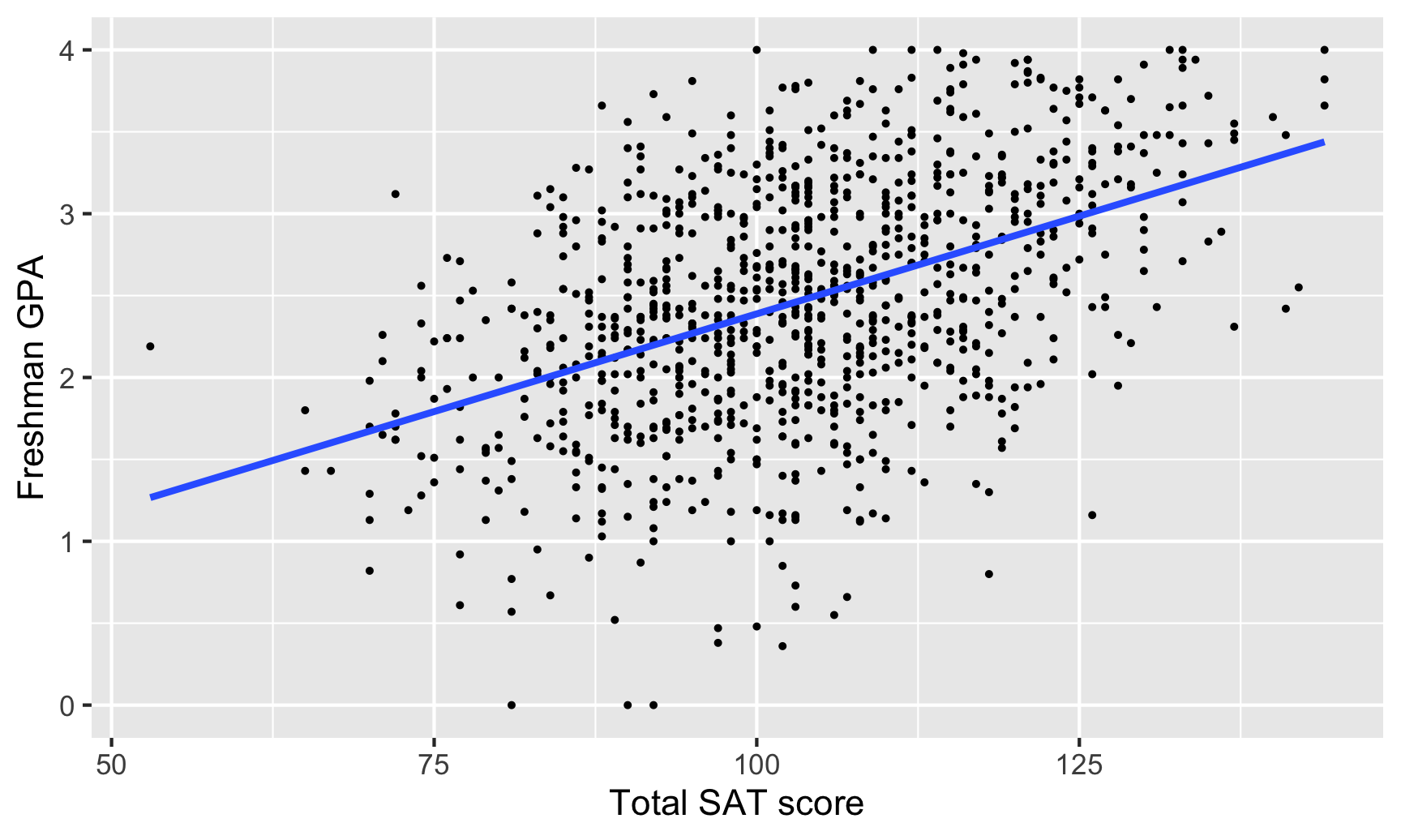
How well does high school GPA correlate with freshman GPA?
cor(sat_gpa$gpa_fy, sat_gpa$gpa_hs)## [1] 0.54High school and freshman GPAs are also moderately correlated (r = 0.54), but with a slightly stronger relationship.
Here’s what that relationship looks like:
ggplot(sat_gpa, aes(x = gpa_hs, y = gpa_fy)) +
geom_point(size = 0.5) +
geom_smooth(method = "lm", se = FALSE) +
labs(x = "High school GPA", y = "Freshman GPA") 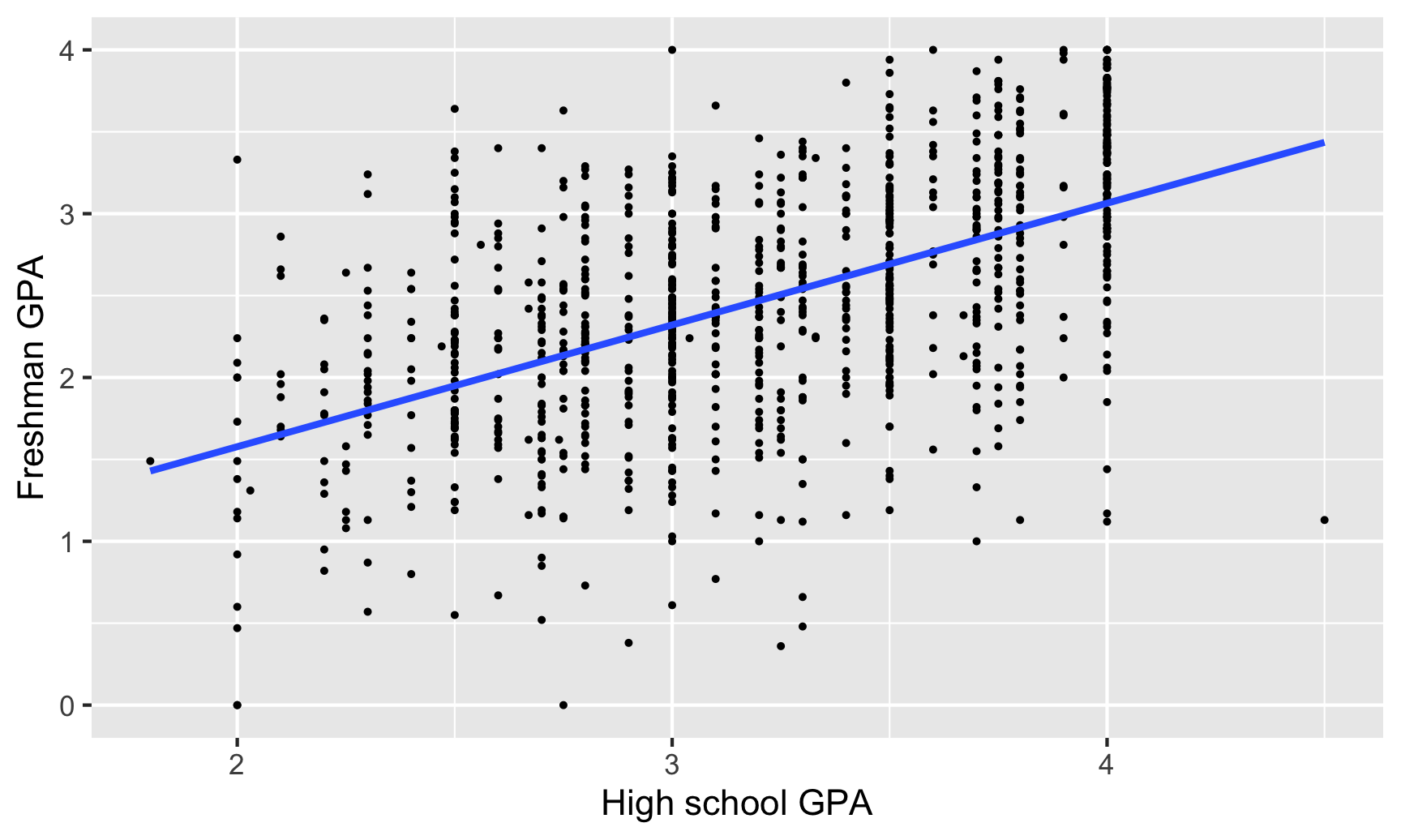
Is the correlation between SAT scores and freshman GPA stronger for men or for women?
# We can calculate the correlation for subgroups within the data with slightly
# different syntax. Notice how this uses the pipe (%>%), which makes it read
# like English. We can say "Take the sat_gpa data set, split it into groups
# based on sex, and calculate the correlation between sat_total and gpa_fy in
# each of the groups
sat_gpa %>%
group_by(sex) %>%
summarize(correlation = cor(sat_total, gpa_fy))## `summarise()` ungrouping output (override with `.groups` argument)## # A tibble: 2 x 2
## sex correlation
## <chr> <dbl>
## 1 Female 0.493
## 2 Male 0.481We can calculate the correlation between SAT scores and freshman GPA for both sexes to see if there are any differences. The correlation is slightly stronger for women, but it’s hardly noticeable (r = 0.49 for females, r = 0.48 for males)
This is apparent visually if we include a trendline for each sex. The lines are essentially parallel:
# The only difference between this graph and the earlier two is that it is
# coloring by sex
ggplot(sat_gpa, aes(x = gpa_hs, y = gpa_fy, color = sex)) +
geom_point(size = 0.5) +
geom_smooth(method = "lm", se = FALSE) +
labs(x = "High school GPA", y = "Freshman GPA")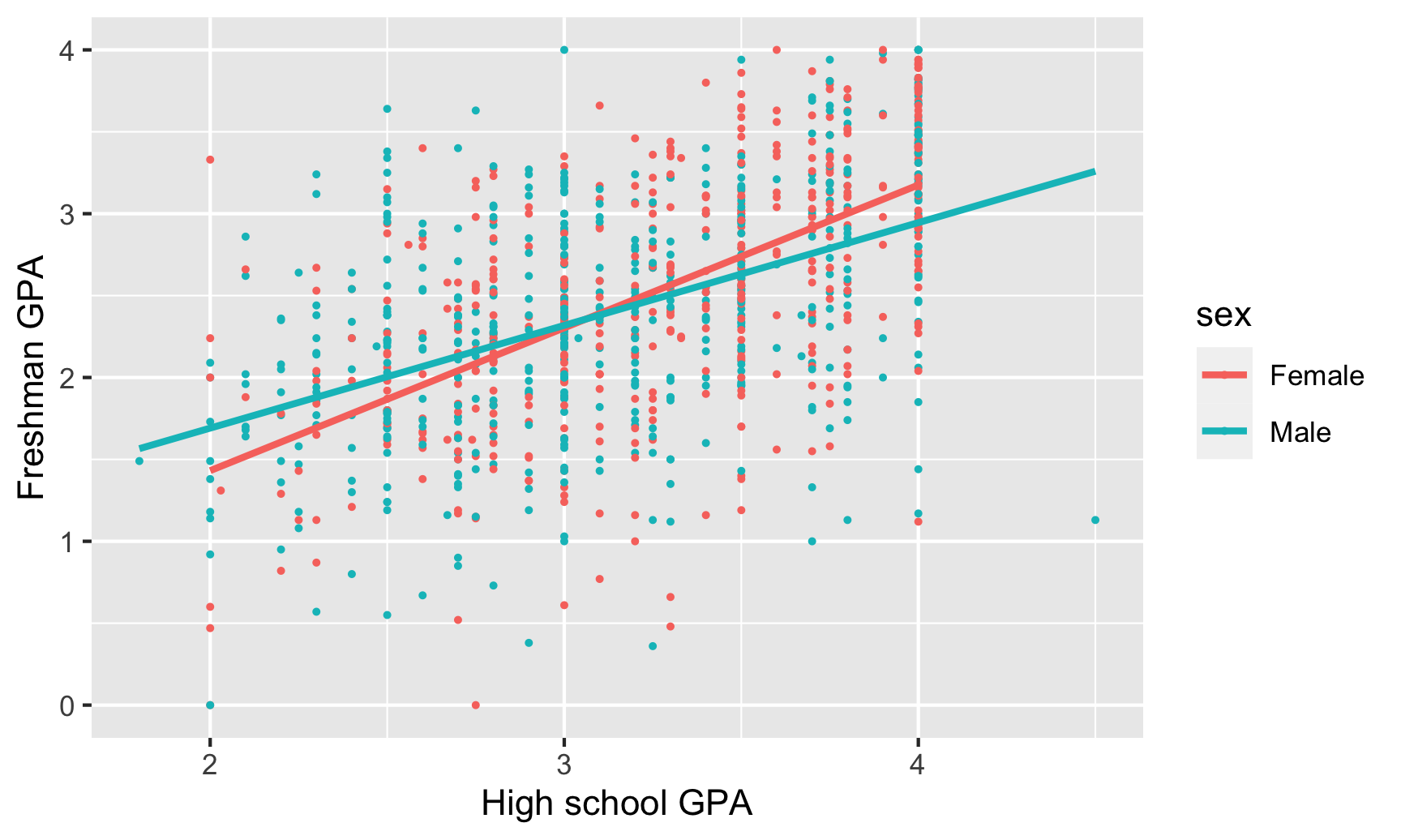
Is the correlation between high school GPA and freshman GPA stronger for men or for women?
sat_gpa %>%
group_by(sex) %>%
summarize(correlation = cor(gpa_hs, gpa_fy))## `summarise()` ungrouping output (override with `.groups` argument)## # A tibble: 2 x 2
## sex correlation
## <chr> <dbl>
## 1 Female 0.597
## 2 Male 0.483There is a noticeable difference between men and women in the correlation between high school and college GPA. For men, the two are moderately correlated (r = 0.48), while for women the relationship is much stronger (r = 0.60). High school grades might be a better predictor of college grades for women than for men.
Models
Do SAT scores predict freshman GPAs?
We can build a model that predicts college GPAs (our outcome variable, or dependent variable) using SAT scores (our main explanatory variable):
\[ \text{freshman GPA} = \beta_0 + \beta_1 \text{SAT total} + \epsilon \]
model_sat_gpa <- lm(gpa_fy ~ sat_total, data = sat_gpa)
# Look at the model results and include confidence intervals for the coefficients
tidy(model_sat_gpa, conf.int = TRUE)## # A tibble: 2 x 7
## term estimate std.error statistic p.value conf.low conf.high
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 (Intercept) 0.00193 0.152 0.0127 9.90e- 1 -0.296 0.300
## 2 sat_total 0.0239 0.00146 16.4 1.39e-53 0.0210 0.0267Here’s what these coefficients mean:
- The intercept (or \(\beta_0\)) is 0.002, which means that the average freshman GPA will be 0.002 when the total SAT percentile score is 0. This is a pretty nonsensical number (nobody has a score that low), so we can ignore it.
- The slope of
sat_total(or \(\beta_1\)) is 0.024, which means that a 1 percentile increase in SAT score is associated with a 0.024 point increase in GPA, on average.
We can look at the summary table of the regression to check the \(R^2\):
glance(model_sat_gpa)## # A tibble: 1 x 12
## r.squared adj.r.squared sigma statistic p.value df logLik AIC BIC deviance df.residual nobs
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <int> <int>
## 1 0.212 0.211 0.658 268. 1.39e-53 1 -999. 2005. 2019. 432. 998 1000The \(R^2\) here is 0.212, which means that SAT scores explain 21% of the variation in freshman GPA. It’s not a fantastic model, but it explains some stuff.
Does a certain type of SAT score have a larger effect on freshman GPAs?
The sat_total variable combines both sat_math and sat_verbal. We can disaggregate the total score to see the effect of each portion of the test on freshman GPA, using the following model:
\[ \text{freshman GPA} = \beta_0 + \beta_1 \text{SAT verbal} + \beta_2 \text{SAT math} + \epsilon \]
model_sat_gpa_types <- lm(gpa_fy ~ sat_verbal + sat_math, data = sat_gpa)
tidy(model_sat_gpa_types, conf.int = TRUE)## # A tibble: 3 x 7
## term estimate std.error statistic p.value conf.low conf.high
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 (Intercept) 0.00737 0.152 0.0484 9.61e- 1 -0.291 0.306
## 2 sat_verbal 0.0254 0.00286 8.88 3.07e-18 0.0198 0.0310
## 3 sat_math 0.0224 0.00279 8.04 2.58e-15 0.0169 0.0279Again, the intercept is meaningless since no student has a zero on both the verbal and the math test. The slope for sat_verbal (or \(\beta_1\)) is 0.025, so a one percentile point increase in the verbal SAT is associated with a 0.025 point increase in GPA, on average, controlling for math scores. Meanwhile, a one percentile point increase in the math SAT (\(\beta_2\)) is associated with a 0.022 point increase in GPA, on average, controlling for verbal scores. These are essentially the same, so at first glance, it doesn’t seem like the type of test has substantial bearing on college GPAs.
The adjusted \(R^2\) (which we need to look at because we’re using more than one explanatory variable) is 0.211, which means that this model explains 21% of the variation in college GPA. Like before, this isn’t great, but it tells us a little bit about the importance of SAT scores.
glance(model_sat_gpa_types)## # A tibble: 1 x 12
## r.squared adj.r.squared sigma statistic p.value df logLik AIC BIC deviance df.residual nobs
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <int> <int>
## 1 0.212 0.211 0.658 134. 2.36e-52 2 -999. 2006. 2026. 432. 997 1000Do high school GPAs predict freshman GPAs?
We can also use high school GPA to predict freshman GPA, using the following model:
\[ \text{freshman GPA} = \beta_0 + \beta_1 \text{high school GPA} + \epsilon \]
model_sat_gpa_hs <- lm(gpa_fy ~ gpa_hs, data = sat_gpa)
tidy(model_sat_gpa_hs)## # A tibble: 2 x 5
## term estimate std.error statistic p.value
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 (Intercept) 0.0913 0.118 0.775 4.39e- 1
## 2 gpa_hs 0.743 0.0363 20.4 6.93e-78The intercept here (\(\beta_0\)) is 0.091, which means that a student with a high school GPA of zero would have a predicted freshman GPA of 0.091, on average. This is nonsensical, so we can ignore it. The slope for gpa_hs (\(\beta_1\)), on the other hand, is helpful. For every 1 point increase in GPA (i.e. moving from 2.0 to 3.0, or 3.0 to 4.0), there’s an associated increase in college GPA of 0.743 points, on average.
The \(R^2\) value is 0.295, which means that nearly 30% of the variation in college GPA can be explained by high school GPA. Neat.
glance(model_sat_gpa_hs)## # A tibble: 1 x 12
## r.squared adj.r.squared sigma statistic p.value df logLik AIC BIC deviance df.residual nobs
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <int> <int>
## 1 0.295 0.295 0.622 418. 6.93e-78 1 -943. 1893. 1908. 386. 998 1000College GPA ~ SAT + sex
Next, we can see how both SAT scores and sex affect variation in college GPA with the following model:
\[ \text{freshman GPA} = \beta_0 + \beta_1 \text{SAT total} + \beta_2 \text{sex} + \epsilon \]
model_sat_sex <- lm(gpa_fy ~ sat_total + sex, data = sat_gpa)
tidy(model_sat_sex, conf.int = TRUE)## # A tibble: 3 x 7
## term estimate std.error statistic p.value conf.low conf.high
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 (Intercept) -0.0269 0.149 -0.181 8.57e- 1 -0.319 0.265
## 2 sat_total 0.0255 0.00145 17.6 1.14e-60 0.0227 0.0284
## 3 sexMale -0.274 0.0414 -6.62 6.05e-11 -0.355 -0.193Here, stuff gets interesting. The intercept (\(\beta_0\)) is once again nonsensical—females with a 0 score on their SAT would have a -0.027 college GPA on average. There’s a positive effect with our \(\beta_1\) (or sat_total), since controlling for sex, a one percentile point increase in SAT scores is associated with a 0.026 point increase in freshman GPA, on average. If we control for SAT scores, males see an average drop of 0.274 points (\(\beta_2\)) in their college GPAs.
The combination of these two variables, however, doesn’t boost the model’s explanatory power that much. The adjusted \(R^2\) (which we must look at because we’re using more than one explanatory variable) is 0.243, meaning that the model explains a little over 24% of the variation in college GPAs.
glance(model_sat_sex)## # A tibble: 1 x 12
## r.squared adj.r.squared sigma statistic p.value df logLik AIC BIC deviance df.residual nobs
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <int> <int>
## 1 0.245 0.243 0.644 162. 1.44e-61 2 -978. 1964. 1983. 414. 997 1000College GPA ~ SAT + high school GPA + sex
Finally we can see what the effect of SAT scores, high school GPA, and sex is on college GPAs all at the same time, using the following model:
\[ \text{freshman GPA} = \beta_0 + \beta_1 \text{SAT total} + \beta_2 \text{high school GPA} + \beta_3 \text{sex} + \epsilon \]
model_sat_hs_sex <- lm(gpa_fy ~ sat_total + gpa_hs + sex, data = sat_gpa)
tidy(model_sat_hs_sex, conf.int = TRUE)## # A tibble: 4 x 7
## term estimate std.error statistic p.value conf.low conf.high
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 (Intercept) -0.836 0.148 -5.63 2.35e- 8 -1.13 -0.544
## 2 sat_total 0.0158 0.00150 10.5 9.72e-25 0.0129 0.0188
## 3 gpa_hs 0.545 0.0394 13.8 6.61e-40 0.467 0.622
## 4 sexMale -0.143 0.0391 -3.66 2.66e- 4 -0.220 -0.0664We can say the following things about these results:
- Yet again, the intercept (\(\beta_0\)) can be safely ignored. Here it means that a female with a 0.0 high school GPA and an SAT score of 0 would have a college GPA of -0.84, on average. That’s pretty impossible.
- The \(\beta_1\) coefficient for
sat_totalindicates that taking into account high school GPA and sex, a one percentile point increase in a student’s SAT score is associated with a 0.016 point increase in their college GPA, on average. - Controlling for SAT scores and sex, a one point increase in high school GPA is associated with a 0.545 point (this is \(\beta_2\)) increase in college GPA, on average. This coefficient is lower than the 0.74 point coefficient we found previously. That’s because SAT scores and sex soaked up some of high school GPA’s explanatory power.
- Taking SAT scores and high school GPAs into account, males have a 0.143 point lower GPA in college, on average (this is \(\beta_3\))
As always, the adjusted \(R^2\) shows us how well the model fits overall (again, we have to look at the adjusted \(R^2\) because we have more than one explanatory variable). In this case, the model explains 36.5% of the variation in college GPA, which is higher than any of the previous models (but not phenomenal, in the end).
glance(model_sat_hs_sex)## # A tibble: 1 x 12
## r.squared adj.r.squared sigma statistic p.value df logLik AIC BIC deviance df.residual nobs
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <int> <int>
## 1 0.367 0.365 0.590 192. 2.67e-98 3 -890. 1790. 1815. 347. 996 1000Which model best predicts freshman GPA? How do you know?
As you’ve learned in previous stats classes, adjusted \(R^2\) generally shows the strength of a model’s fit, or how well the model will predict future values of the outcome variable. If we compare the adjusted \(R^2\) for each of the models, we see that the “best” model is the last one.
# The modelsummary() function takes a bunch of different regression models and
# puts them in a neat side-by-side table. In a normal report or analysis, you'd
# include all of these once instead of going one by one like we did above.
modelsummary(list(model_sat_gpa, model_sat_gpa_types, model_sat_gpa_hs,
model_sat_sex, model_sat_hs_sex))| Model 1 | Model 2 | Model 3 | Model 4 | Model 5 | |
|---|---|---|---|---|---|
| (Intercept) | 0.002 | 0.007 | 0.091 | -0.027 | -0.836 |
| (0.152) | (0.152) | (0.118) | (0.149) | (0.148) | |
| sat_total | 0.024 | 0.026 | 0.016 | ||
| (0.001) | (0.001) | (0.002) | |||
| sat_verbal | 0.025 | ||||
| (0.003) | |||||
| sat_math | 0.022 | ||||
| (0.003) | |||||
| gpa_hs | 0.743 | 0.545 | |||
| (0.036) | (0.039) | ||||
| sexMale | -0.274 | -0.143 | |||
| (0.041) | (0.039) | ||||
| Num.Obs. | 1000 | 1000 | 1000 | 1000 | 1000 |
| R2 | 0.212 | 0.212 | 0.295 | 0.245 | 0.367 |
| R2 Adj. | 0.211 | 0.211 | 0.295 | 0.243 | 0.365 |
| AIC | 2004.8 | 2006.4 | 1893.0 | 1963.8 | 1790.2 |
| BIC | 2019.5 | 2026.0 | 1907.7 | 1983.4 | 1814.8 |
| Log.Lik. | -999.382 | -999.189 | -943.477 | -977.904 | -890.108 |
| F | 268.270 | 134.244 | 418.071 | 161.762 | 192.141 |
This is real data about real students, compiled and cleaned by a professor at Dartmouth.↩︎